Anglický překlad si můžete přečíst zde.
Za dlouhá léta, co používám k sazbě všeho možného Latex, jsem svoje nastavení Biblatexu vypiloval k dokonalosti. (Mám nejkrásnější citace v celičkém povodí Moravy.😉) Když jsem nedávno přešel na Typst (modernější sazečský systém, který člověka nenutí trhat si tolik vlasy), jedna z věcí, která mě překvapila, byla právě – dle mého mínění – nepěkná bibliografie. Zde je můj zbastlený pokus tenhle problém vyřešit!
Bibliografie v Typstu
Prvně je potřeba (alespoň zběžně) vysvětlit, jak v Typstu funguje bibliografie. Z uživatelského hlediska je to poměrně jednoduché: Ke konci dokumentu prostě člověk dá příkaz k vytištění citačních záznamů (bibliografie), ve kterém specifikuje soupis literatury a styl záznamů:
#bibliography("bibliografie.bib", style: "ieee")@jirasek[str. 12].
Bum, bác, hotovo.
Na rozdíl od Latexu se člověk nemusí starat o několikanásobnou kompilaci ani o to, jaký balík použít.
Soupis literatury může být buď v souboru .bib, který používá i Biblatex, nebo v souboru .yml ve formátu Hayagriva.
Hayagriva se zdá být formátem kanonickým, takže pokud člověk používá biblatexový formát, při načítání dojde ke konverzi.¹
(Aktuálně nejde o konverzi bezztrátovou:
Může se ztratit pole note.)
Několik citačních stylů má Typst vestavěných (například APA, IEEE či anglickou variantu ISO 690). Pokud ovšem člověk chce nějaký jiný citační styl, musí Typstu dát soubor ve formátu CSL, který daný styl popisuje. (Pomocí CSL se dají definovat pravidla typu: Vypiš příjmení autorů verzákami, vypiš název díla kurzívou atp.) A odsud tkví můj problém s tvorbou bibliografie v Typstu: Přestože existuje několik CSL implementací (mé preferované citační normy) ISO 690, žádná z nich mi nevyhovuje. (Například implementace české varianty ISO 690, kterou jsem našel, používá u časopisů krátké číslování místo dlouhého (tj. 10(2) místo roč. 10, č. 2). Jak u stylu vestavěného, tak i u stylů z internetu se vyskytly chybějící tečky a mezery atd.) Implementovat IS0 690 sám nebo upravit cizí styl si ovšem netroufám, protože práce s CSL je – jak by řekl klasik – strašné voser.
Bastleníčko bastlení
Kdybych podobný problém měl v Latexu, mohl bych si citace napsat ručně (a případně si je nechat vygenerovat nějakým skriptem).
V Typstu ale manuální citace dělat nejdou.²
To mě ale nemohlo zastavit.
Po chvilce přemýšlení jsem vyplodil tenhle diagram:
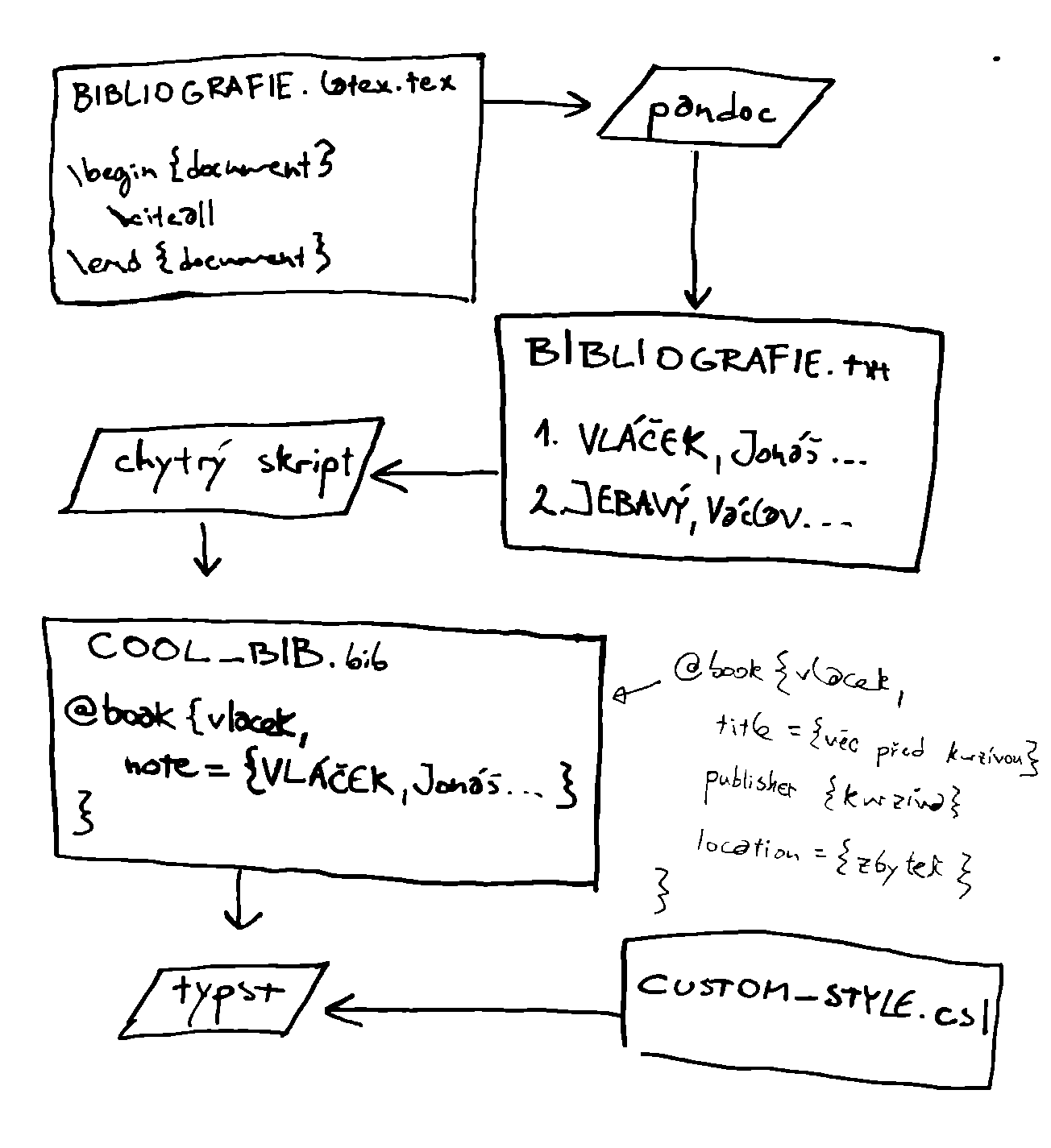 Plán práce byl tedy takový:
Plán práce byl tedy takový:
- vytvořit citační záznamy v prostém textu;
- nasypat takhle předtvořené záznamy do falešného souboru
.bibnebo.yml; - vysázet je v Typstu pomocí vlastního CSL.
Krok 1: Vytvoření záznamů
Prvně je tedy potřeba vytvořit samotné citační záznamy.
Maje seznam děl jazykověda.bib, jal jsem se vytvořit latexový soubor citace.tex, který
vytiskne pouze citační záznamy.
Ten vypadal zhruba takto:
první verze souboru
citace.tex\documentclass{scrartcl}
\usepackage[czech]{babel}
\usepackage[
backend = biber,
style = iso-numeric
]{biblatex}
\addbibresource{jazykověda.bib}
\begin{document}
\pagenumbering{gobble}
\nocite{*}
\printbibliography[env = mypubs, heading = none]
\end{document}
Latex tenhle kód přeloží na několikastranný seznam (krásných) citačních záznamů.
Já jsem se ale spouštění Latexu chtěl vyhnout. Latexu totiž překlad kódu na PDF trvá dlouho. (Mimochodem, Typst PDFka tvoří svižně.) Zeptá-li se člověk internetového vyhledávače, jak přetvořit latexový kód na prostý text, dostane jednoduchou odpověď: Použij Pandoc! Zkusil jsem to. Prvním příkazem
pandoc
citace.tex
-f latex
-t html
--verbose -s
-o citace.html
--bibliography jazykověda.bibpandoc
citace.tex
-f latex
-t html
--verbose -s
-o citace.html
--citepro
--bibliography jazykověda.bib Ono se asi není čemu divit:
Pandoc latexový kód nepřekládá.
Pouze z kódu vybírá text, různá prostředí přeskakuje a citace formátuje pomocí CSL.
Ono se asi není čemu divit:
Pandoc latexový kód nepřekládá.
Pouze z kódu vybírá text, různá prostředí přeskakuje a citace formátuje pomocí CSL.
Pandoc nevyšel.
Rozhodl jsem se tedy vytvořit Latexem PDF a to převést do prostého textu utilitou pdftotext.
Prvně jsem musel upravit latexový kód, aby v PDFku nebyl »bordel«, který by se přelil do prostého textu.
Nový soubor citace.tex vypadal takhle:
druhá verze souboru
citace.tex\documentclass[
fontsize = 9
]{scrartcl}
\usepackage[czech]{babel}
\usepackage{geometry}
\usepackage[utf8]{inputenc}
\usepackage[
unicode,
hidelinks
]{hyperref}
\usepackage[
maxbibnames = 5,
maxcitenames = 3,
mincitenames = 1,
uniquename = init,
uniquelist = false,
backend = biber,
style = iso-numeric,
sorting = none,
articlepubinfo = true,
mincrossrefs = 99,
doi = false
]{biblatex}
\addbibresource{jazykověda.bib}
\geometry{
paperheight = 1189mm,
paperwidth = 594mm,
left = 1mm,
right = 1mm,
top = 1mm,
bottom = 1mm
}
\renewcommand*{\mkbibacro}[1]{%
{#1}%
}
\DefineBibliographyStrings{czech}{andothers={a~kol\adddot}}
\DefineBibliographyStrings{slovak}{andothers={a~kol\adddot}}
\DefineBibliographyStrings{english}{andothers={a~kol\adddot}}
\DefineBibliographyStrings{german}{andothers={a~kol\adddot}}
\DefineBibliographyStrings{czech}{bathesis={Bakalářská práce}}
\DefineBibliographyStrings{czech}{mathesis={Diplomová práce}}
\DefineBibliographyStrings{czech}{phdthesis={Dizertační práce}}
\DefineBibliographyStrings{czech}{
editor = {ed\adddot},
editors = {ed\adddot},
bytranslator = {Překlad},
}
\DefineBibliographyStrings{english}{
editor = {ed\adddot},
editors = {ed\adddot},
bytranslator = {Překlad},
}
\DefineBibliographyStrings{german}{
editor = {ed\adddot},
editors = {ed\adddot},
bytranslator = {Překlad},
}
% \let\familynameformat=\textsc
\DefineBibliographyStrings{czech}{
page={str.},
pages={str.},
}
\DeclareNameAlias{bytranslator}{given-family}
\newbibmacro{titles}[2]{%
\ifboolexpr{
test {\iffieldundef{#1title}}
and
test {\iffieldundef{#1subtitle}}}
{}
{\printtext[#2]{%
¦%
\printfield{#1title}%
\setunit{\subtitlepunct}%
\printfield{#1subtitle}}%
\setunit{\addspace}}%
¦%
\printfield{#1titleaddon}%
\newunit
}%
% https://tex.stackexchange.com/a/138886
\defbibenvironment{mypubs}
{\list
{}
{\setlength{\leftmargin}{\bibhang}%
\setlength{\itemindent}{-\leftmargin}%
\setlength{\itemsep}{\bibitemsep}%
\setlength{\parsep}{\bibparsep}}}
{\endlist}
{\item}
\begin{document}
\pagenumbering{gobble}
\nocite{*}
\leavevmode
\printbibliography[env = mypubs, heading = none]
\end{document}
Výstupní PDFko vypadalo takhle a překonvertované na prostý text vypadalo takhle.
PDF soubor citace.pdf má jenom jednu stránku kvůli výše zmíněnému »bordelu«.
Názvy knih a časopisů jsou odděleny znaky ¦ kvůli následnému parsování.
V souboru citace.txt každému záznamu odpovídá jeden řádek, přičemž záznamy jsou seřazeny stejně jako v jazykověda.bib.
Krok 2: Falešný .bib
Dalším krokem bylo narvat vygenerované citační záznamy do »falešného« seznamu děl.
Každý řádek (citační záznam) ze souboru citace.txt jsem rozdělil na tři části:
- část před kurzívou (tj. jména autorů, případně jména autorů a název článku),
- část psanou kurzívou (tj. název knihy, název časopisu),
- část po kurzívě (tj. nakladatelské údaje).
@book{kvan:tesitelova-1987,
title = {TĚŠITELOVÁ, Marie a kol. },
publisher = {O češtině v číslech},
location = {. 1. vyd. Praha: Academia, 1987.}
}
Zde jest skript, kterým jsem to udělal:
skript na vytvoření falešného seznamu děl
#!/usr/bin/env python3
import bibpy
def main():
with open('citace.txt', 'r') as file:
text_input = file.readlines()
lines = [line.strip().split('¦') for line in text_input[:-2]]
bibliography = bibpy.read_file('jazykověda.bib').entries
if len(lines) != len(bibliography):
return 1
for i in range(len(lines)):
if len(lines[i]) == 5:
first_part = lines[i][0] + lines[i][1] + lines[i][2]
middle_part = lines[i][3]
last_part = lines[i][4]
elif len(lines[i]) == 3:
first_part = lines[i][0]
middle_part = lines[i][1]
last_part = lines[i][2]
else:
print('divná délka')
print(f'@book\u007b{bibliography[i].bibkey},')
print(f'\ttitle = \u007b{first_part}\u007d,')
print(f'\tpublisher = \u007b{middle_part}\u007d,')
print(f'\tlocation = \u007b{last_part}\u007d')
print('\u007d')
return
if __name__ == '__main__':
main()
Krok 3: CSL
Poslední, co zbývalo udělat bylo vytvořit CSL styl, který by můj falešný seznam správně vysázel.
Aby pole title vysázel základním písmem, po něm pole publisher kurzívou a pak zase pole location základním písmem.
To naštěstí nebylo tak komplikované jako plnohodnotná implementace ISO 690.
Můj styl fake_bib.csl vypadá takto:
fake_bib.csl<?xml version="1.0" encoding="utf-8"?>
<style xmlns="http://purl.org/net/xbiblio/csl" class="in-text" version="1.0" demote-non-dropping-particle="never" default-locale="cs-CZ">
<info>
<title>Fake BIB</title>
<id>fake_bib</id>
<author>
<name>T. V.</name>
</author>
<category citation-format="numeric"/>
<category field="generic-base"/>
<summary>Fake BIB</summary>
</info>
<citation collapse="citation-number" after-collapse-delimiter="; ">
<sort>
<key variable="citation-number"/>
</sort>
<layout prefix="[" suffix="]" delimiter=", ">
<group delimiter=" ">
<text variable="citation-number"/>
<group delimiter=" ">
<label variable="locator" form="short"/>
<text variable="locator"/>
</group>
</group>
</layout>
</citation>
<bibliography second-field-align="flush">
<layout>
<text variable="citation-number" prefix="[" suffix="] "/>
<text variable="title" suffix=" "/>
<text variable="publisher" font-style="italic" suffix=" "/>
<text variable="publisher-place"/>
</layout>
</bibliography>
</style>
Výsledek
Hotovo! Stačí vygenerovat falešný seznam, spolu s fake_bib.csl ho podstrčit Typstu a mám krásné
citace.
Kuk!
-
Nejde o konverzi per se.
Spíš jde o to, že Typst k načítání používá knihovnu Hayagriva, která sice umí pracovat s biblatexovými soubory, primárně ale pracuje se zmíněnými
.ymlsoubory. - Trošku kecám. Někdo už jeden způsob vymyslel.
- Zkoušel jsem jak konverzi do HTML, tak i do prostého textu.